ONGOING RESEARCH/ PROJECTS
.png/:/cr=t:0%25,l:0%25,w:100%25,h:100%25/rs=w:400,cg:true)
Neural Voice Cloning With few Samples
Voice cloning is a highly desired feature for personalized speech interfaces. We introduce a neural voice cloning system that learns to synthesize a person’s voice from only a few audio samples. We study two approaches: speaker adaptation and speaker encoding. Speaker adaptation is based on fine-tuning a multi-speaker generative model. Speaker encoding is based on training a separate model to directly infer a new speaker embedding, which will be applied to a multi-speaker generative model. In terms of the naturalness of the speech and similarity to the original speaker, both approaches can achieve good performance, even with a few cloning audios. While speaker adaptation can achieve slightly better naturalness and similarity, cloning time, and required memory for the speaker encoding approaches are significantly less, making it more favorable for low-resource deployment.
Visual Reconstruction of Image from Spoken Word using EEG
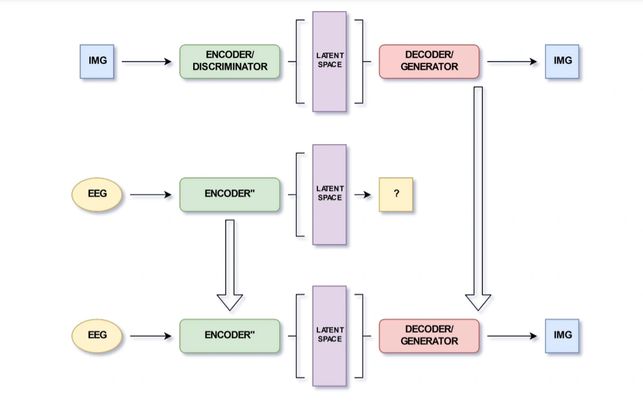
In this project, the main motivation was to construct images from
a person’s spoken words. We have designed and trained a deep
neural network to perform this task using a large data set of people
brain EEG signals. Thus, have collected an EEG dataset consisting of
2000 audio and visualization events which can be used to analyze
temporal visual and auditory responses to spoken word stimuli. And
finally, everything was implemented on the MNIST data set
Generative Modelling of Images from SpeechSpeech2Face

In this project, the main motivation was to infer about a person’s look from the way they speak. We design and train a deep neural network to perform this task using thousands of natural YouTube videos of people speaking. During training, our model learns voice face correlations, and then we used it for voice recognition to evaluate the efficiency of our model. The training is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly.